Bueno, resulta que, el aparentemente simple e inocente problema de las serpientes en realidad es un problema abierto en el área de combinatoria enumerativa.
Antes de plantear el problema que me interesa ahora, primero tengo que platicar cómo no se resuelve el problema de las serpientes.
Lo más natural al intentar resolver el problema es hacer algunos casos pequeños para darse una idea del comportamiento de la sucesión.

Serpientes, con su codificación
Como se sugirió en la entrada anterior, cada serpiende queda codificada por una sucesión de letras, indicando hacia dónde se hacen los giros. Tabulando las cantidad de serpientes para cada longitud tenemos:
1, 2, 4, 6, 10, 16, 26,…
Salvo los dos primeros términos, cada uno es igual a la suma de los dos anteriores, como en los números de Fibonacci. De hecho, salvo el primero todos son el doble de un número de Fibonacci. Vamos a denotar por  el número de serpientes de longitud n y por
el número de serpientes de longitud n y por  al n-ésimo número de Fibonacci. Conjeturamos entonces:
al n-ésimo número de Fibonacci. Conjeturamos entonces:
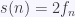 .
.
Fijándonos en las palabras que codifican cada serpiente, si I es un giro hacia la izquierda y D un giro para la derecha, entonces la lista de serpientes comienza como:
 . Sólo hay una palabra, vacía.
. Sólo hay una palabra, vacía. . Hay 2 palabras, indicando los dos posibles giros: I, D.
. Hay 2 palabras, indicando los dos posibles giros: I, D. . Las palabras posibles son II, ID, DI, DD.
. Las palabras posibles son II, ID, DI, DD. . Las palabras válidas son IID, IDI, IDD, DII, DID, DDI. Nótese que III, DDD no son palabras váldias pues hacer 3 giros consecutivos en la misma dirección regresa al punto inicial y por tanto la serpiente se tocaría a sí misma.
. Las palabras válidas son IID, IDI, IDD, DII, DID, DDI. Nótese que III, DDD no son palabras váldias pues hacer 3 giros consecutivos en la misma dirección regresa al punto inicial y por tanto la serpiente se tocaría a sí misma. . Las palabras aquí son IIDI, IIDD, IDII, IDID, IDDI, DIID, DIDI, DIDD, DDII, DDID.
. Las palabras aquí son IIDI, IIDD, IDII, IDID, IDDI, DIID, DIDI, DIDD, DDII, DDID.
Unos casos más podrían convencernos que las serpientes corresponden a palabras donde no hay 3 símbolos consecutivos iguales.
Ahora, antes de seguir hay que aclarar que la descripción anterior sólo es corecta hasta n=11, porque a partir de entonces hay serpientes no válidas que no tienen 3 símbolos seguidos. Por ejemplo:
- IDIIDIIDIID no es una serpiente válida, pues termina en el punto inicial y por tanto se corta a sí misma.

IDIIDIIDIID no tiene 3 símbolos iguales consecutivos
Esto quiere decir que la descripción simple que conjeturamos para las serpientes no es la correcta. De hecho, tampoco es cierta la conjetura de que el número de serpientes siempre es el doble de un número de Fibonacci (y precisamente a partir de n=12 falla la conjetura.
¿Cual es entonces la sucesión real de número de serpientes? ¿Porqué los primeros términos de la sucesión están relacionados con los números de Fibonacci?
Para calcular los valores reales de la sucesión usamos la computadora para generar todos los caminos hasta cierta longitud. El siguiente programa, en el lenguaje de programación Ruby genera todas las posibles serpientes y muestra la sucesión asociada.
#! /usr/bin/ruby
# coding: utf-8
def dir(q,p)
# dirección de p-->q
v=[q[0]-p[0],q[1]-p[1]]
if v == [0,1]
return :N
elsif v==[0,-1]
return :S
elsif v==[1,0]
return :E
elsif v==[-1,0]
return :W
end
end
def mueve(x, d)
if d == :N
return [x[0], x[1]+1]
elsif d == :S
return [x[0], x[1]-1]
elsif d == :E
return [x[0]+1,x[1]]
elsif d == :W
return [x[0]-1,x[1]]
end
return [x[0],x[1]]
end
def gira(d, c)
#puts "girando #{d}"
if c == 1 # giro positivo
if d == :N
return :W
elsif d == :W
return :S
elsif d == :S
return :E
elsif d== :E
return :N
end
elsif c== -1 #giro negativo
if d == :N
return :E
elsif d == :E
return :S
elsif d == :S
return :W
elsif d == :W
return :N
end
end
end
def recorre(s) # Esta función "recorre" una cadena y regresa falso si se corta a sí misma
puntos=[[0,0],[1,0]]
s.downcase!
s.each_char{ |c|
p=puntos[-2]
q=puntos[-1]
diractual = dir(q,p)
if c == "d"
newdir=gira(diractual, -1)
elsif c=="i"
newdir=gira(diractual, 1)
elsif c=="a"
newdir = diractual
end
a=puntos[-1]
b=mueve(a,newdir)
if puntos.include?(b)
return false
break
else
puntos << b
end
}
return s
end
def main #Aquí generamos todas las serpientes
levels=[""]
print "1"
0.upto(20){ |n| #Iteramos sobre todas las longitudes
past=levels
new=[]
past.each{ |s| # Y para cada una de longitud n-1, intentamos extenderla
if recorre(s+"i") then new << s+"i" end
if recorre(s+"d") then new << s+"d" end
#if recorre(s+"a") then new << s+"a" end # Activar esta línea para permitir avanzar sin girar
#puts "level #{n} genera #{new}"
}
print ", #{new.length}" # Finalmente mostramos cuántas hubo en ese nivel
levels = new
}
end
main
El resultado de correr el programa es
1, 2, 4, 6, 10, 16, 26, 42, 68, 110, 178, 282, 452, 724, 1160, 1842, 2936, 4688, 7480, 11844, 18826, 29956
que difiere de la sucesión de dobles de Fibonacci a partir de la posición 12.
1, 2, 4, 6, 10, 16, 26, 42, 68, 110, 178, 288, 466, 754, 1220, 1974, 3194, 5168, 8362, 13530, 21892, 35422
Podemos consultar datos sobre la segunda sucesión en la base de datos OEIS











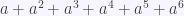
 indica que sólo hay 1 forma de obtener
indica que sólo hay 1 forma de obtener 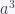 .
.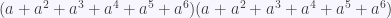

 en el desarrollo de
en el desarrollo de 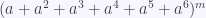 es el número de formas de obtener el valor k al tirar m dados y con esta información podemos encontrar el valor exacto.
es el número de formas de obtener el valor k al tirar m dados y con esta información podemos encontrar el valor exacto.
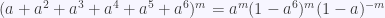
 en
en 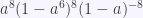 . Es decir, es el coeficiente de
. Es decir, es el coeficiente de  en
en  . Usando el teorema del Binomio (primero para exponentes enteros y luego para exponentes negativos) tenemos
. Usando el teorema del Binomio (primero para exponentes enteros y luego para exponentes negativos) tenemos ,
, ,
, .
. en el desarrollo de
en el desarrollo de
